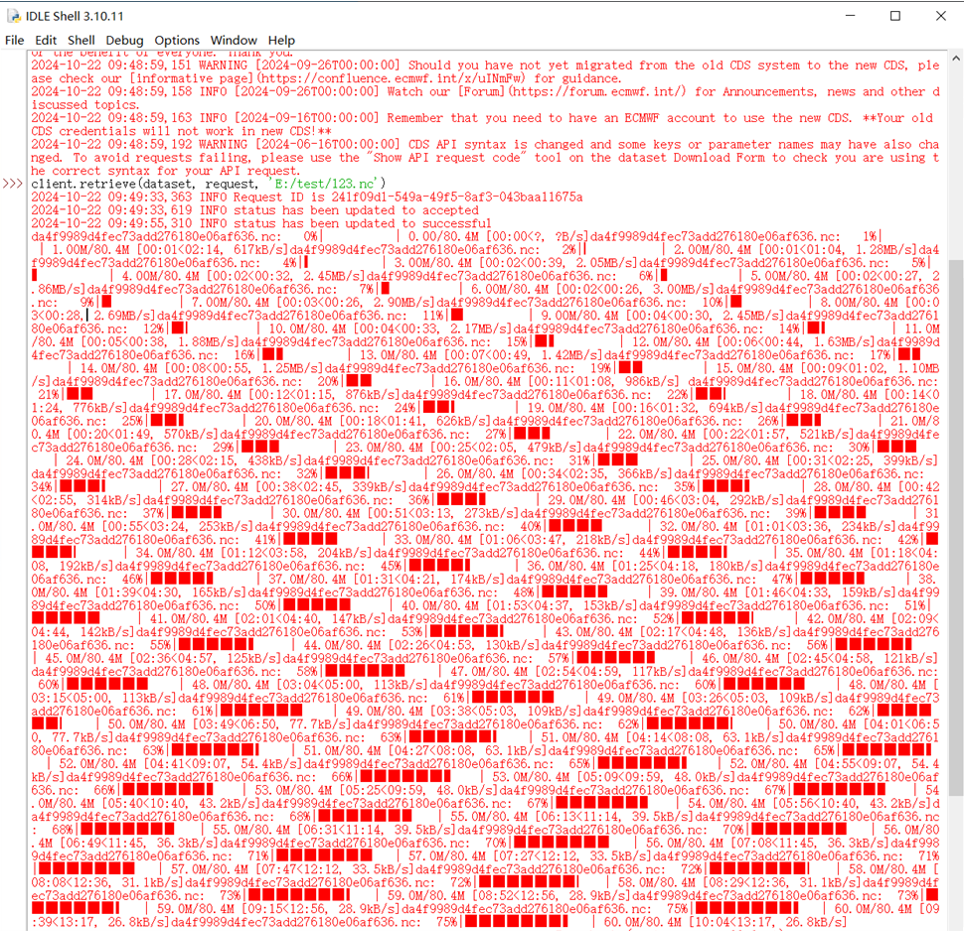
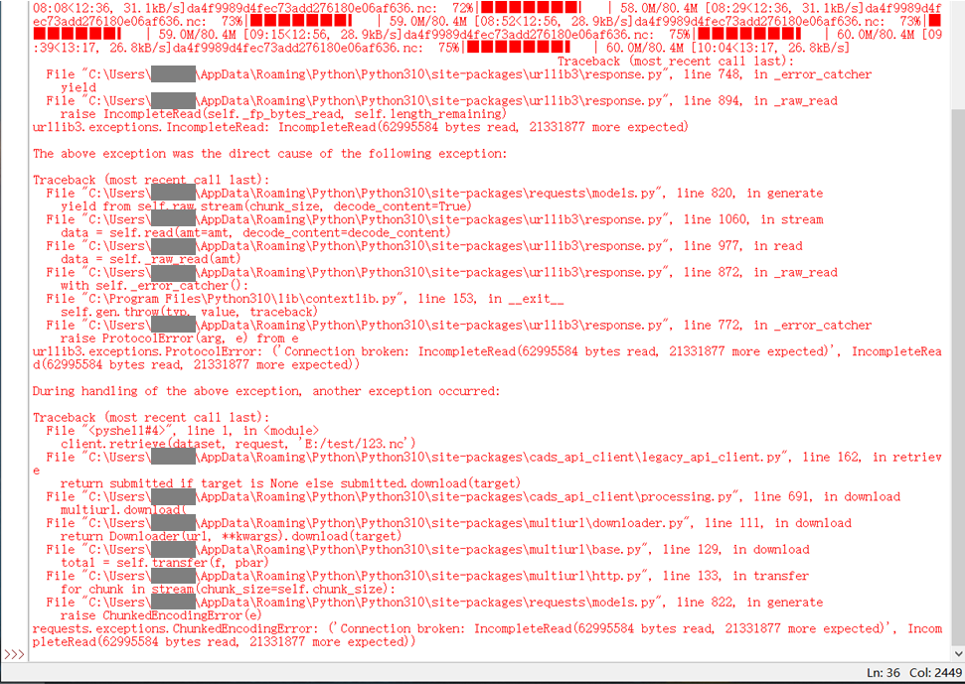
I have a similar problem with very slow downloading speed. Basically, the size of data downloaded via CDS API is 2.1MB, but it takes 45 minutes. This is unusual because I can download data of more than 2GB when using the ecmwfapi for that amount of time. Additionally, I found that if the data size beyond 2.1MB or 20MB. For example, I increased the area to for the area size by increasing longitude 9 degrees. Error always occur:
KeyboardInterrupt
or
Exception: the request you have submitted is not valid. One or more variable sizes violate format constraints.
But with small data size, I can download data.
Below is my code for retrieving ERA5 data:
code start
import calendar
import cdsapi
server = cdsapi.Client()
def retrieve_era5():
"""
A function to demonstrate how to iterate efficiently over several years and months etc
for a particular era5_request.
Change the variables below to adapt the iteration to your needs.
You can use the variable 'target' to organise the requested data in files as you wish.
In the example below the data are organised in files per month. (eg "era5_daily_201510.grb")
"""
yearStart = 1998
yearEnd = 1998
monthStart = 1
monthEnd = 1
for year in range(yearStart, yearEnd + 1):
Year = str(year)
for month in range(monthStart, monthEnd + 1):
Month = str(month)
# startDate = '%04d-%02d-%02d' % (year, month, 1)
numberOfDays = calendar.monthrange(year, month)[1]
Days = [str(x) for x in list(range(1, numberOfDays + 1))]
# lastDate = '%04d-%02d-%02d' % (year, month, numberOfDays)
target = "era5_1h_daily_0to70S_100Eto120W_025025_quv_%04d%02d.nc" % (year, month)
# requestDates = (startDate + "/" + lastDate)
era5_request(Year, Month, Days, target)
def era5_request(Year, Month, Days, target):
"""
An ERA era5 request for analysis pressure level data.
Change the keywords below to adapt it to your needs.
(eg to add or to remove levels, parameters, times etc)
"""
server.retrieve('reanalysis-era5-pressure-levels',
{'product_type': 'reanalysis',
'format': 'netcdf',
'variable': ['specific_humidity', 'u_component_of_wind', 'v_component_of_wind'],
'year': Year,
'month': Month,
'day': Days,
'pressure_level': ['300', '350', '400','450', '500', '550', '600', '650', '700','750', '775', '800','825', '850', '875','900', '925', '950','975', '1000'],
'time': ['00:00', '01:00', '02:00','03:00', '04:00', '05:00','06:00', '07:00', '08:00','09:00', '10:00', '11:00','12:00', '13:00', '14:00','15:00', '16:00', '17:00','18:00', '19:00', '20:00','21:00', '22:00', '23:00'],
'area': [0, 100, -1, 101],},
target)
if name == 'main':
retrieve_era5()
code end
This code is just to do things small at first, try to download specific_humidity, u_component_of_wind, v_component_of_wind from 1998-1-1 to 1998-1-31, temporal resolution: 1 hour; spatial resolution: 0.25° x 0.25°; pressure levels: 300 hpa to 1000 hpa. Area :1°S to 0, 100°E to 101°E.
Below is the picture showing the results of running this code:
Below is the picture showing that downloading data by ecmwfapi, basically, 23minutes retrieving 2.18GB data:
When changing the 'area': [0, 100, -1, 101] to 'area': [0, 100, -70, 101] it works fine. But when changing the 'area': [0, 100, -1, 101] to 'area': [0, 100, -70, 130]. error occurred.
KeyboardInterrupt or Exception: the request you have submitted is not valid. One or more variable sizes violate format constraints.
I thought this might be due to limit, I did the same through the website, it shows the data size is under the limit.
So I do not know what is going on?