I wanted to ask if there is a preferred or recommended approach for downloading bulk data. I’ve been tasked to download 46 years of hourly data for 10 variables from the global ERA5 single level 0.25° resolution dataset (“reanalysis-era5-single-levels”). These are going to be used to drive a set of different plant productivity models for a model intercomparison.
I’m making requests through the API using python.
I’m requesting monthly single variable subsets. That is 10 variables x 46 years x 12 months = 5220 requests of about 1.5GB each for around 8TB total.
I am using the cdsswarm package as a wrapper around cdsapi to automate the submission process. The package design does seem to be honouring the spirit of the underlying cdsapi conditions since it principally seems to be about detaching the download process from the task processing, but I do also have a one-at-a-time script (links below)
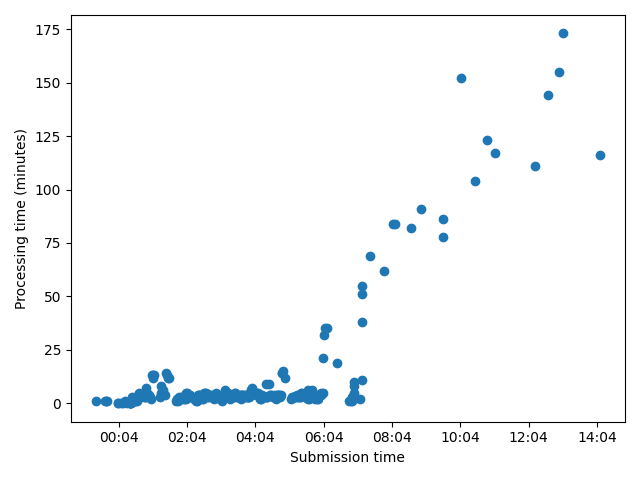
The download is running but after a while there has been a marked increase in processing time: the plot below shows the submission time of each request versus total processing time in minutes:
I think my requests must have passed some threshold for being throttled. I completely get that the CDSAPI needs to manage limited resources across multiple users. I also understand that this is a very large request, but we do want to able to examine model performance at a global scale.
Do you have a recommended approach to handle large downloads? With dynamic prioritisation on the server, it is very hard to know how best to package requests - is it better to go with fewer larger requests or is there a daily limit we should stay under? Alternatively is there a download endpoint for bulk data where users just get a particular fixed packaging (global years by variable) without any of the elegant API subsetting?
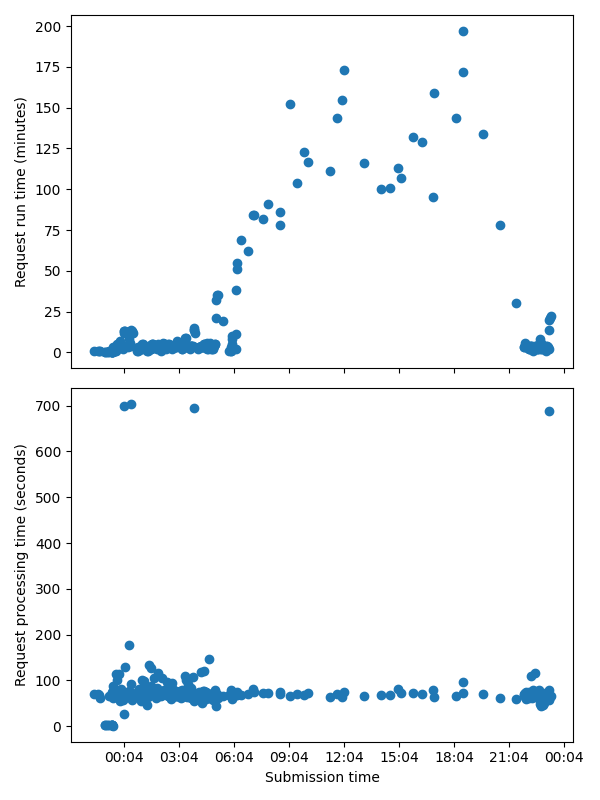
Just to follow up, this process was running as a 24hr job on our HPC queue. I’ve used the new ecmwf-datastores-client to automatically grab the updated set of completed requests (nice functionality by the way!) and get the data below. The actual request processing time is basically completely static. It looks like the throttling is removed at some point and restores the unthrottled performance.
It’s hard to plan data downloads without some understanding of what triggers throttling - it is particularly tricky for us because we’re downloading using qsub on our HPC, so the job runtimes are fixed.
Yes, it’s fantastic to see ARCO data becoming available for ERA5. This is essentially how we’ve been processing & storing ERA5 / ERA5Land data for the past 5 years and it’s great to see agencies such as ECMWF adopt ARCO formats.
Just to let you know that the ARCO ERA5 and ERA5-land data is now fully published and documented on the CDS dataset pages. Please see this announcement for more details: