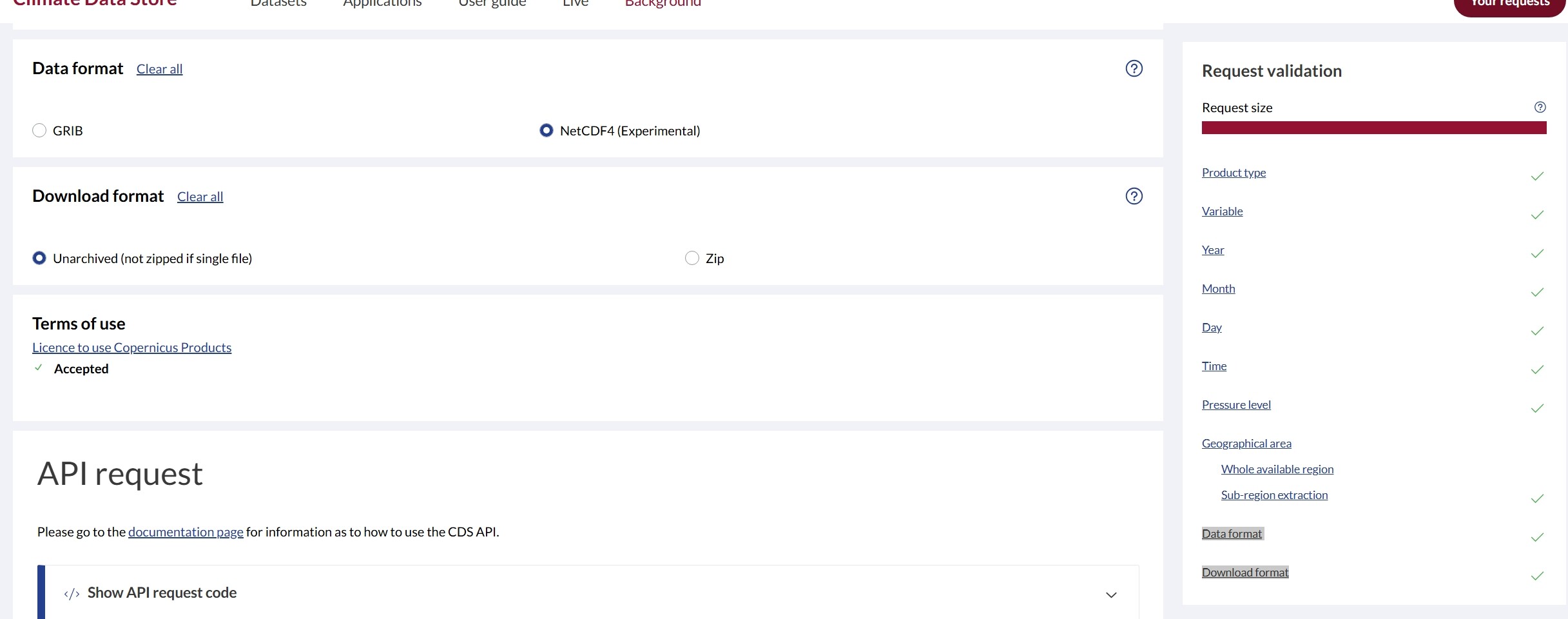
Has the way that request size is calculated changed? I have made calls for one month and 11 variables of era5-land hourly data earlier today and it worked without issue, but now it is saying my request is too large for the same call. The request is not too large if I select to output it as a GRIB format, but it is too large as netcdf. What has changed?
Facing the same Issue. The data size cross the limit when it is taken for netcdf while for grip file it is less. It is tremendously increasing !!!. Initially it is working for the same datasets size. Would like to know if it gonna resolve?
I have also encountered the same problem, can you solve it? This has greatly affected my work.
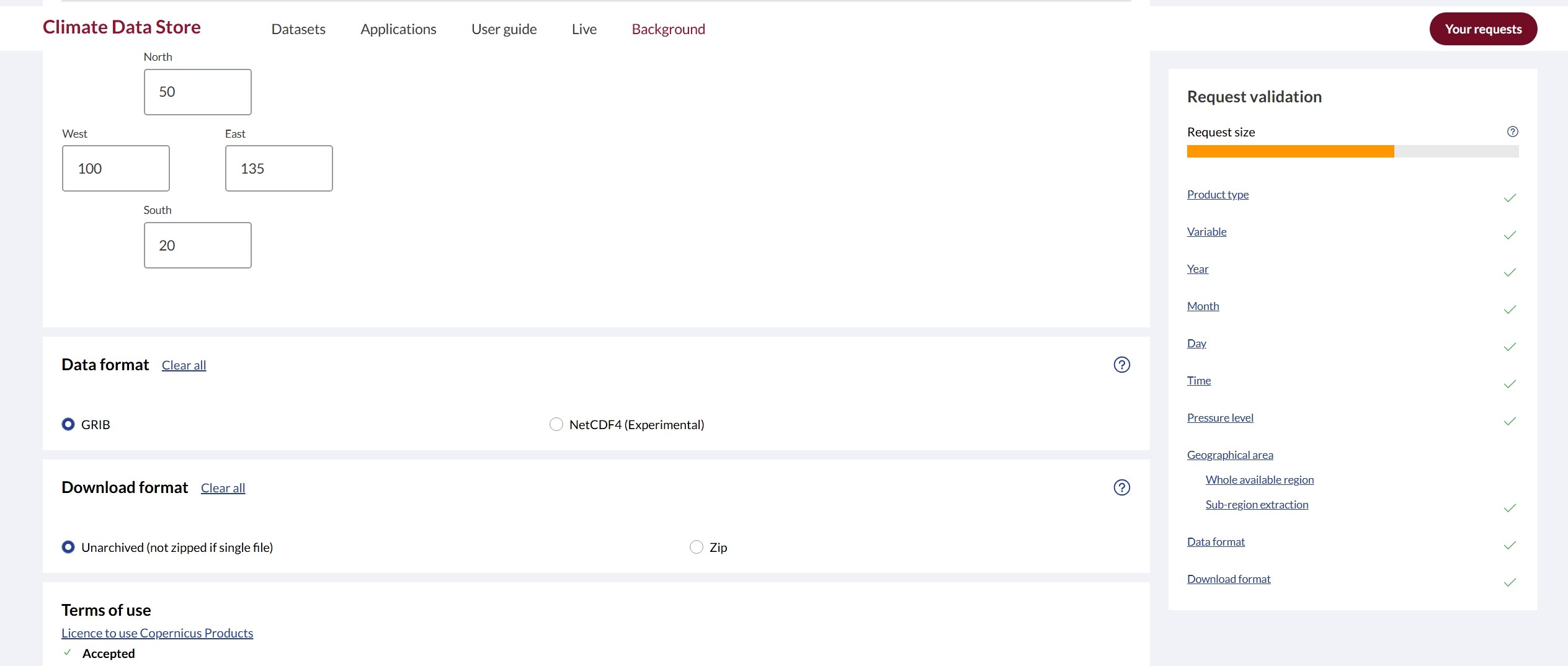
I have similar problem. On March 26 I downloaded data (netcdf). Now similar data seems to be much larger and if I tried to download the same data as on March 26 I got: Request too large. Cost 460800 over 60000 limit. Please, reduce your selection.
same problem! hopefully it is going to be resolved soon
I am also facing the same issue starting on March 26, even though I have been running the same code to download the same size of data for months now. Hope we get an update on this issue soon.
I seem to be experiencing this issue as well. I am using this script to access 5 months of data for 1 year for all pressure levels for just 1 variable , and it is saying the request is too large. I am pretty sure I have used this successfully in the past, so I don’t know why it is too large now. Downloading each month for each year separately in manual form is certainly not ideal.
import cdsapi
import os
client = cdsapi.Client()
VARS_MAPPING = {'v_component_of_wind': '131.128'}
YEARS = ['1982'] # Modify as needed
MONTHS = ['11', '12', '01', '02', '03'] # The months you want
for V in VARS_MAPPING:
for Y in YEARS:
target_filename = f'era5-hourly-{V}-{Y}.nc'
target_directory = '/scratch/areed29/transport_ERA5/'
filepath = os.path.join(target_directory, target_filename)
if not os.path.isfile(filepath):
client.retrieve(
'reanalysis-era5-pressure-levels',
{
'variable': V,
'product_type': 'reanalysis',
'year': Y,
'month': MONTHS,
'day': [f'{i:02d}' for i in range(1, 32)], # Days 01-31
'time': ['00:00', '06:00', '12:00', '18:00'], # 4 times per day
'pressure_level': [str(p) for p in [1, 2, 3, 5, 7, 10, 20, 30, 50, 70,
100, 125, 150, 175, 200, 225, 250,
300, 350, 400, 450, 500, 550, 600,
650, 700, 750, 775, 800, 825, 850,
875, 900, 925, 950, 975, 1000]], # Pressure levels as strings
'format': 'netcdf',
'area': [90, -180, 0, 180], # North, West, South, East
},
filepath
)
Same issue! I need to run 6 times more queries and get 6 times more files.
Also, for some reason, hourly ERA5LAND adds one day after the requested period, making a mess in timeline.
I am experiencing the same problem. Please resolve it ASAP!
Same here, I’m experiencing 403 error through the API, and I can see the cost multiplication in the web interface when I switch from grib to netcdf.
Another user experiencing the same issue here. Been running the same script to download data for more than 2 years. Now need to reduce the number of pressure levels, all of a sudden.
Same issue here. I have been using API to download ERA5 data in netcdf format, but now I cannot download even a single variable for just a single month.
It looks like nobody’s reading our posts. The error was reported a week ago, and there are no signs that @copernicus is aware of.
I’m regularly puzzzled by the absence of moderators / ecmwf technical staff on this forum - having at least some aknowledgement that the issue is real / confirmed / under investigation would be much appreciated indeed!
Hi,
please see the last announcement: Limitation change on netCDF ERA5 requests
Thanks
Hi Michela, Thank you for the confirmation. At least, we know that it is not an error but a new reality.
In this respect, please also clarify how to glue these downloaded files correctly, keeping in mind the error in timestamp.
Might this be because for total precipitation if you want the total of day D, you need to check time 00:00 of D+1? (Something i will never understand, if you ask me)
With precipitation, it is even worse: 23 hour shift. Only one observation comes from the first day, and 23 hour observations are added from the date following the last requested.
And back to your comment, it is clear why they made this strange decision with cumulative precipitation hours. Day 1 starts at 00:00 and nothing fell from the sky during this fraction of a second. At 01:00 we collect some water in our bucket and can assign this precipitation to 1:00. … Then, at 23:00, the day 1 is still not over, and rain continues. Thus, the total volume for this day 1 will be observed at 24:00 (and this timestamp doesn’t exist, it is equal to day 2 00:00).
The other question, why they give us these cumulative values? It would be easier for all of us to process hourly data, naturally assigned like all 0:00-0:59 precipitation to assign to 0:00 time stamp, … 23:00-23:59 to assign to 23:00 stamp.
I understand that logic, but i think the logic of: I want to know how much it rained on day D (plus the temperature and whatsoever more), i am gonna download day D should be way more important. Downloading day D for other variables and D+1 for cummulative makes no sense, and tweaks lots of internal logics in automated processes.