I’m downloading single levels hourly data for ERA5, the submitted requests are always in Queued state and the Queued state lasts for hours. Anyone else experiencing this? How should I handle this kind of problem?
2 Likes
I had a similar problem.
I’ve now been queuing for over 12 hours and still can’t download it.
1 Like
I also have a similar question
I have the same problem.
I’ve been queuing for over 3 hours now.
1 Like
I had a similar problem. Have your the problem OK?
Judging by the status page the pipeline is either stuck or it is fully congested by a few large requests. I’ll try to get in touch with somebody to get some info in that.
The “Running requests” is stuck on 424 since my last update. The queue sice continues to grow up steadily. I can also see now that number of requests completed is declining for past few hours. In last hour, the system did not ship any data.
I contacted the support (CUS-26507) and it is in state “Waiting for support”. I received an email notifying me that they will respond to the request during the office hours. The confluence page said the office hours are 08:00 - 17:00 UTC. That starts in about an hour and a half.
EDIT: I cannot post any more to this thread so I’m updating this message. I got a response to my request. I hope they don’t mind me pasting it here.
The information we have is that the CDS service is currently degraded; You can check “Data Stores” status here.
There were issues after the CDS system session yesterday which meant that requests were not being processed. They are trying to fix it and have reverted some of the changes, so that at least some requests can be processed. Users are advised that there may be delays to their requests.
4 Likes
I have ERA5 requests in queue for days and the next error appears: requests.exceptions.SSLError: HTTPSConnectionPool(host=‘cds.climate.copernicus.eu’, port=443): Max retries exceeded with url: /api/retrieve/v1/jobs/c1dcaa2e-561c-4630-bc7b-42cf0b183eb2?log=True (Caused by SSLErr
or(SSLEOFError(8, ‘EOF occurred in violation of protocol (_ssl.c:1129)’)))
That might still be ok. Looks like you’re using Python to grab the files. I suspect it uses one long-lived connection to the CDS servers and somebody just restarted the servers so the connection was dropped. You can still download the data from the website manually.
1 Like
I think the CDS may have slowed down over the past couple days, and gotten really slow today.
See comment over on ERA5-CDSAPI-Extremely Slow download - #2 by Andrew_Janke - C3S - Datasets and Usage - Forum.
Looking at the live CDS system status page, about an hour ago I saw this, showing a decline in daily volumes over the last couple days, and 0 downloads in the last hour.
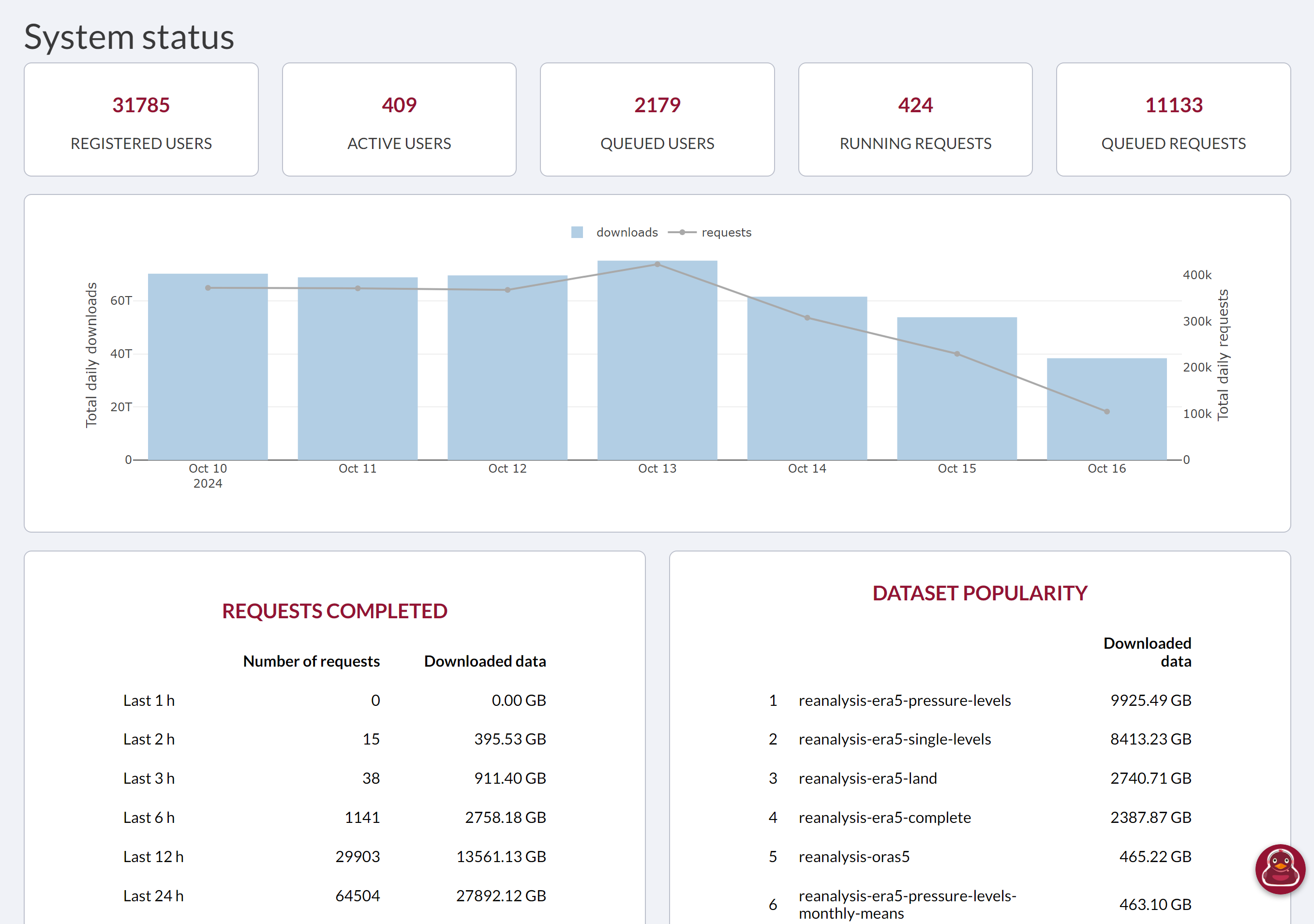
Dunno if the metrics data for this page is delayed, and “0 downloads last 1 h” is a normal thing to see.
But I looked again just now, about 40 minutes after that last check, and now the “0 downloads” has rolled into the “last 2 h” bucket. So I think it might be real, and maybe the CDS is stuck.
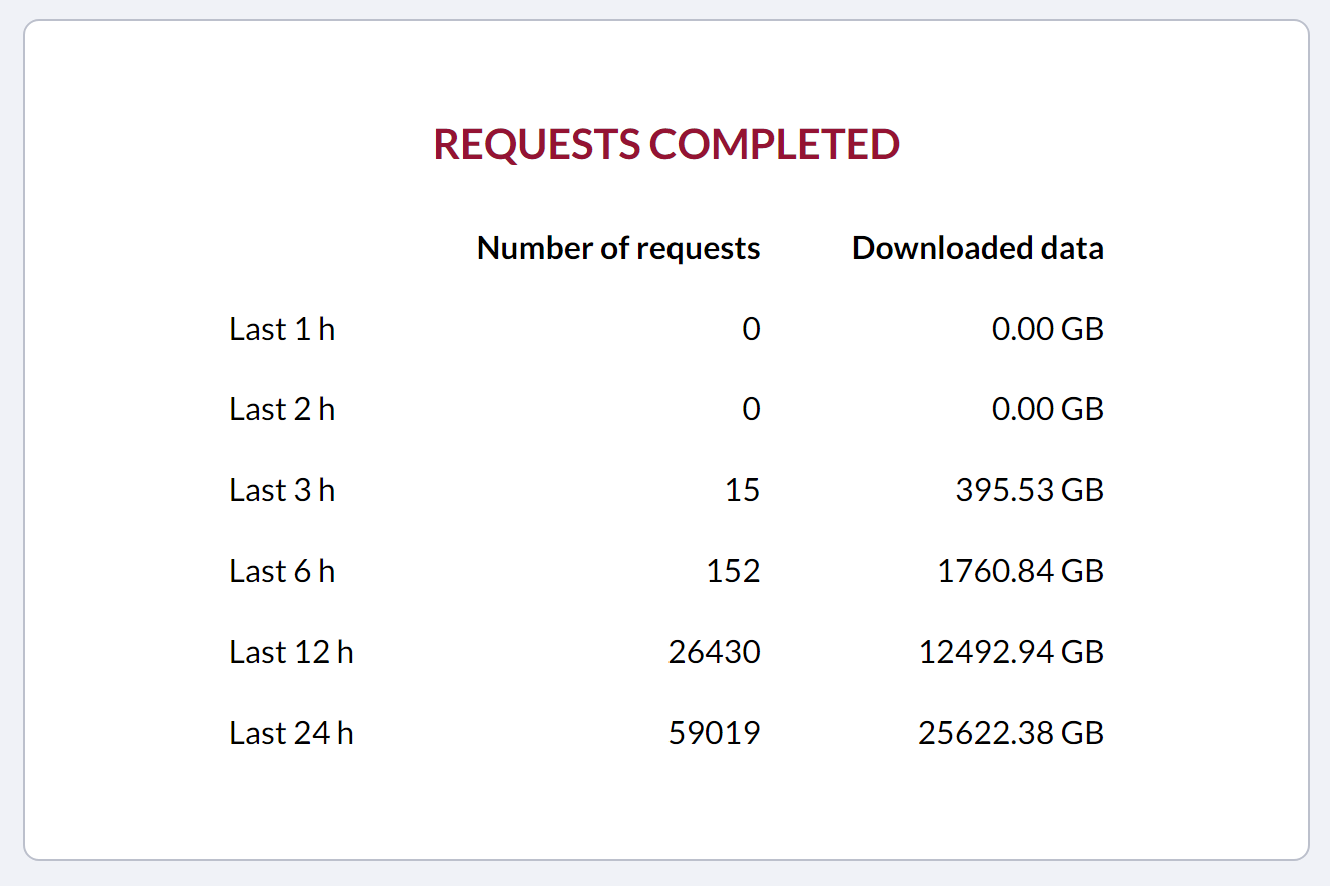
ECMWF CDS support folks, if you’re reading this: could you maybe add a timestamp display to that live system status page, so that when users take and share screenshots of it like this, the info about when the snapshot was taken is included in the image? Like, maybe up at the top next to the users & requests account, or above it as part of the “System status” header? Got a couple other minor suggestions on my other comment, if you want to take a look at those too.
5 Likes
Thank you very much, this is very helpful for me to confirm the stuck state of CDS.