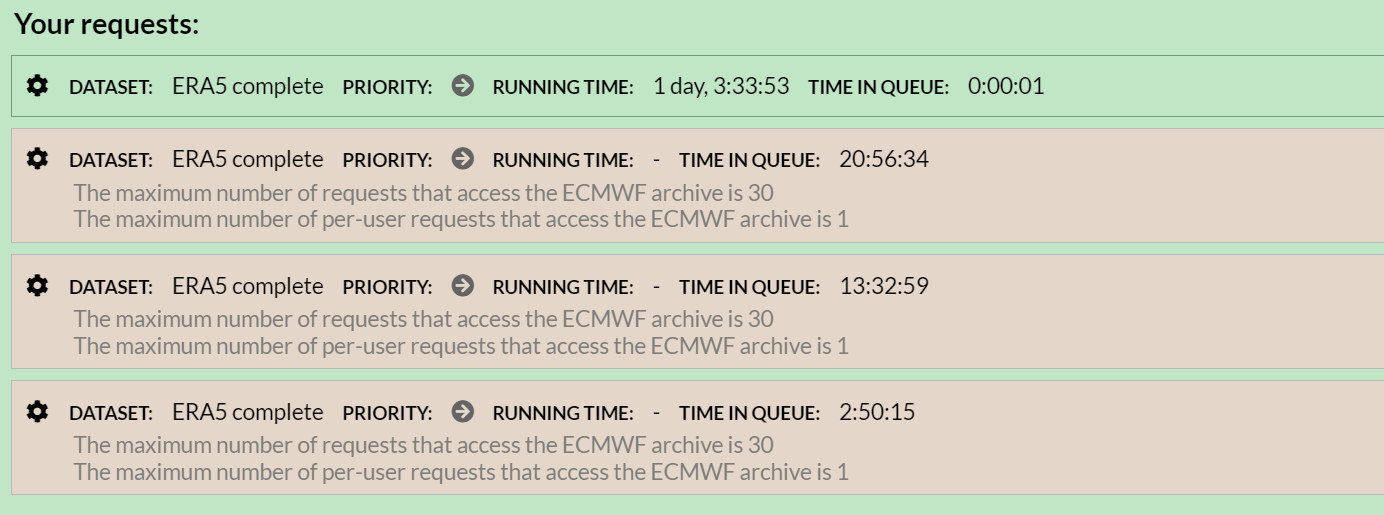
Hello.
I am still seeing that pulling hourly runoff from cds/Copernicus is potentially prohibitively slow. Perhaps one year of data per day. Yet it varies, and apparently at least in part as a function of user load/demand.
And, it occasionally hangs up, seemingly somewhat at random.
Please advise?
Here is a sample script (which appears to work just fine through sometimes a few months, then I get a timeout, sometimes through years, then I get a timeout…). I follow it with a sample error I have gotten after, e.g., a timeout.
"import cdsapi
c = cdsapi.Client()
def is_leap_year(year):
return (year % 4 == 0) and (year % 100 != 0) or (year % 400 == 0)
def days_in_month(month):
if month == 1 or month == 3 or month == 5 or month == 7 or month == 8 or month == 10 or month == 12:
return 31
elif month == 2:
if is_leap_year(year):
return 29
else:
return 28
else:
return 30
for year in range(1979,2020):
for mon in range(1,13):
for day in range(1,days_in_month(mon)+1):
if (day < 10):
theday="0"+str(day)
else:
theday=str(day)
if (mon < 10):
themon="0"+str(mon)
else:
themon=str(mon)
for time in range(0,24):
if (time < 10):
thetime="0"+str(time)
else:
thetime=str(time)
print("Year, month, day, time: ",str(year),themon,theday,thetime)
c.retrieve("reanalysis-era5-single-levels", {
"product_type": "reanalysis",
"format": "netcdf",
"variable": "runoff",
"year": str(year),
"month": themon,
"day": theday,
"time": thetime
}, "output."+str(year)+str(themon)+str(theday)+str(thetime)+".nc")"
Error:
“requests.exceptions.ReadTimeout: HTTPSConnectionPool(host='cds.climate.copernicus.eu', port=443): Read timed out. (read timeout=60)”
Sorry if I'm doing something wrong! Thanks much in advance for any advice.
Best,
Michael